損失関数をただ見つめたい人へ——OSSメトリクストラッカーAsparaを公開しました
PredNextは本日、機械学習実験向けメトリクストラッカー AsparaをOSSとして公開 しました。
Asparaは、静かに豊かに損失関数を見つめたい人のための新しいメトリクストラッカーです。こだわったのは次の2つです。
- 損失関数のグラフ画面に最短でたどり着けること
- グラフの更新がリアルタイムで、かつ高速であること
Asparaでは、標準的なWebダッシュボードに加えて、TUIダッシュボードも用意しました。好みの方をお使いください。
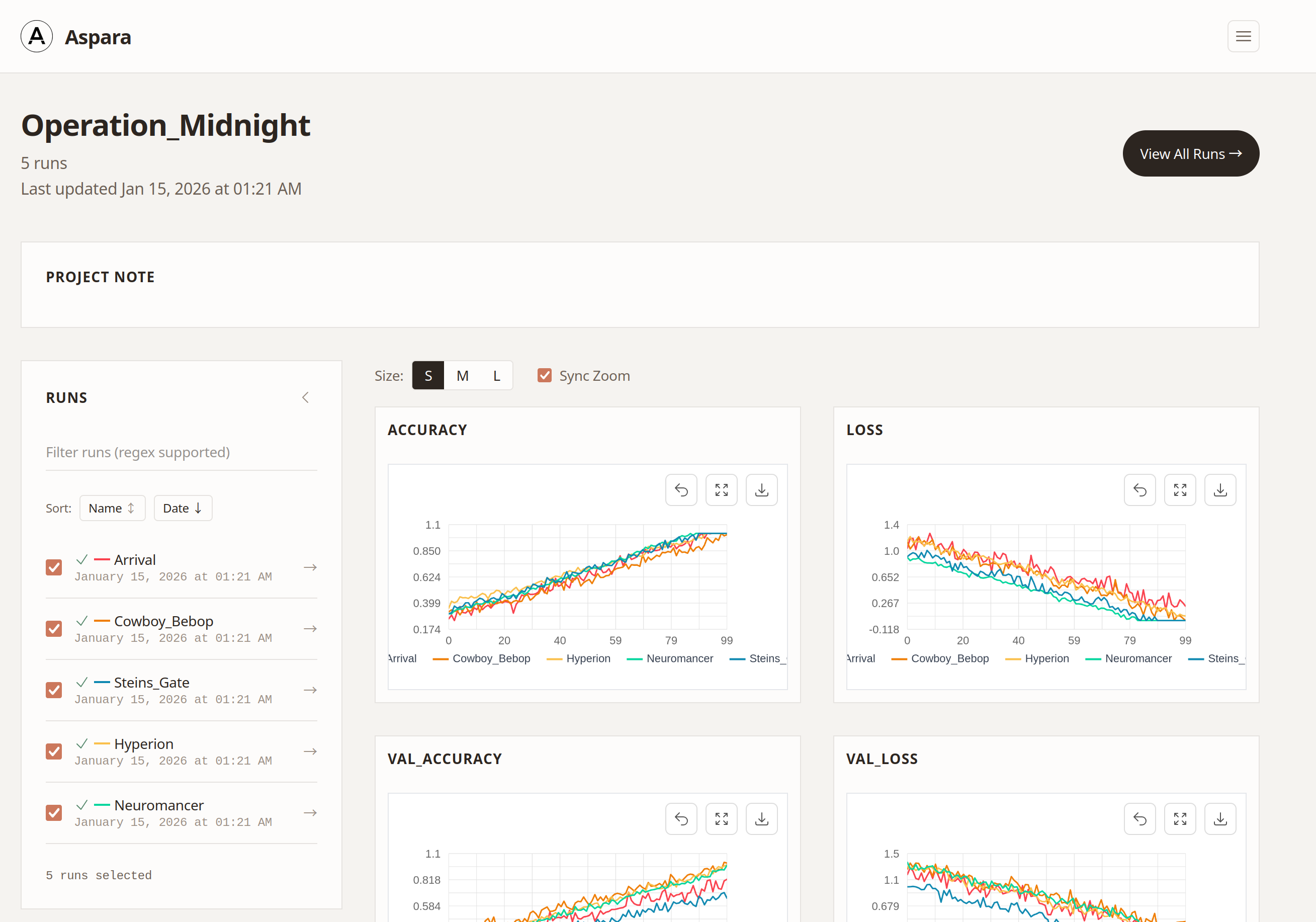
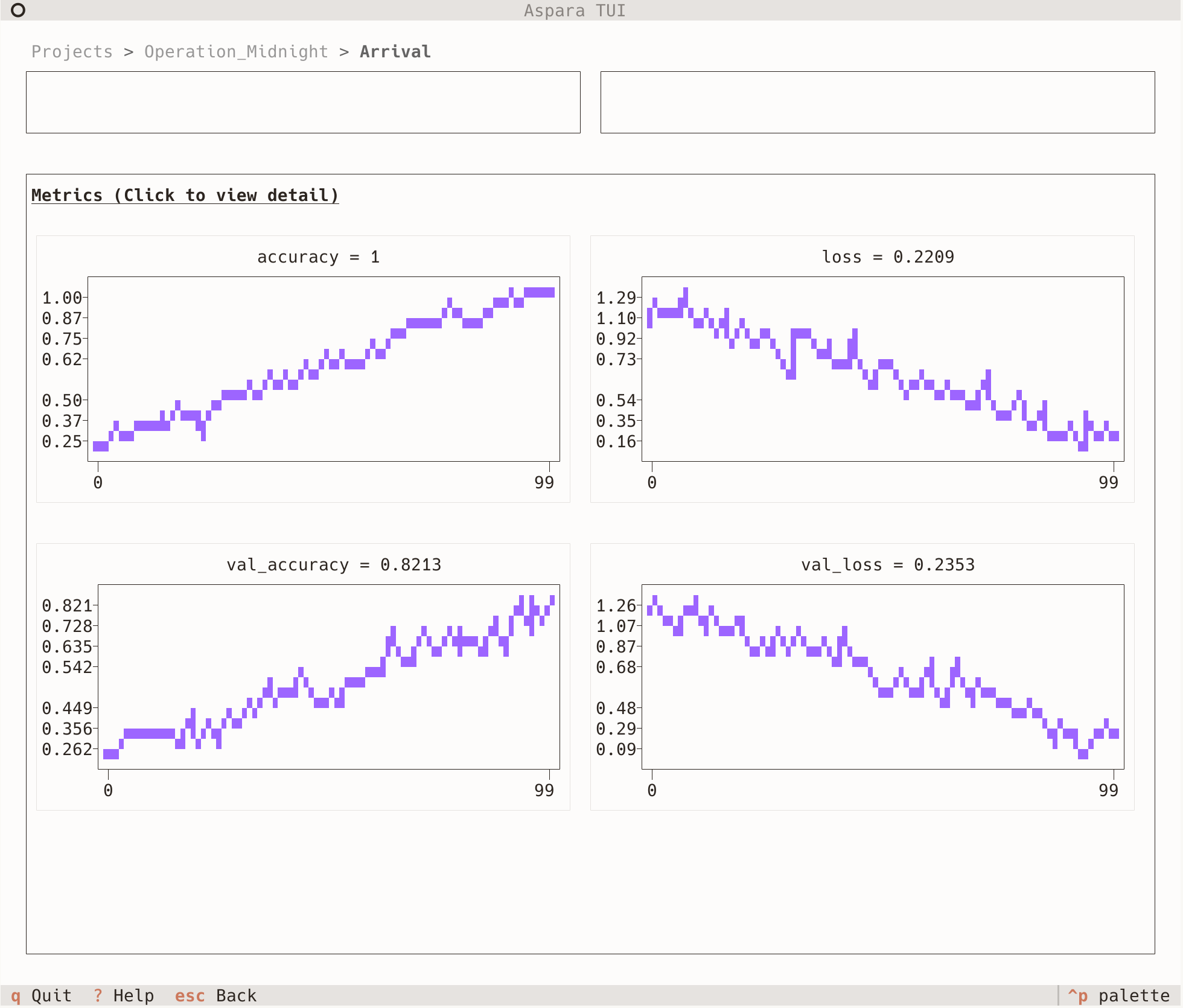
Asparaにはいくつかの工夫が採用されていますが、今回は、もっとも特徴的なLargest Triangle Three Buckets(LTTB)について解説します。
LTTBによるダウンサンプリング
Asparaに実装されている高速化の工夫のうち、特に効いているのがLTTBによるデータの間引き(ダウンサンプリング)です。大量のメトリクスでも画面の応答性を保つために、メトリクスの全データはブラウザに渡さず、表示に必要な分だけを転送します。
ただし、単純に間引くだけだと、大事な変化を見落とすかもしれません。メトリクストラッカーでは平均よりも外れ値が重要です。損失関数にスパイクが出ているなら、そこは拾いたい。そこでAsparaでは、外れ値を残すためにLTTBを採用しています。
LTTBでは、データをいくつかのバケット(区間)に分割し、バケット単位で代表点を選択します。
まず最初と最後のバケットは、それぞれ最初の点と最後の点を使います。2つ目以降のバケットの代表点を決める際には、
- 前のバケットの代表点(A、この場合は最初の点ですね)
- 今のバケット内の候補点(B)
- 次のバケットの平均座標(C)
この3点で作る三角形の面積を計算し、面積が最も大きくなる候補点を、今のバケットの代表点として選択します。3つ目以降は同じ計算を繰り返します。

LTTBの計算量は、データ点数をNとしたときO(N)です。LTTBを採用したことで、元データが数十MB程度になっても、ブラウザに送るデータ量はその1/100程度に圧縮され、数十ミリ秒程度で転送できるようになりました。
便利なLTTBですが、万能というわけではありません。一つ前のバケットの代表点が決まらないと、今見ているバケットの代表点が計算できないため、完全にnumpyだけで計算することが難しく、Pythonでのループが必要になるため、少し計算が重くなります。今後、この部分はRustで書き直すか、もしくは並列度を上げるためにアルゴリズム自体に手を入れるか、ともかく、もっと改善していきたいと考えています。もっと速くなる余地があるので、今後にご期待ください。
メトリクスの記録方法
Asparaは標準設定ではローカルディスクにメトリクスを記録しますが、リモートサーバーのアドレスを指定することで、HTTP(S)経由でメトリクスを送信することもできます。クライアントライブラリは現状ではPython用しか存在しませんが、将来的には他の言語向けのクライアントライブラリも提供していく予定です。
開発を振り返って
Asparaのコードの約99%はClaude CodeとWindsurfで書きました。Asparaの開発は実質2か月ほどでしたが、この速度で今回のリリースにこぎつけられたのは、LLMがコードを書いてくれたおかげです。
開発にはいろいろな困難がありました。一番困難だったのは、チャート描画部分です。私はCanvasにはあまり詳しくないので、チャート描画部分は完全にClaudeに任せたのですが、なかなかうまくいきませんでした。初期バージョンは去年の2月頃に開発していたのですが、Web版のClaudeに50回くらい書き直してもらいました。(その直後にClaude Codeが出ました。)
二番目に困難だったのは、チャートの動的更新です。inotifyでファイルの更新を監視しているのですが、初期実装ではrunファイルごとに監視をつけてしまい、ファイルディスクリプタが足りなくなって、すぐに更新を検出できなくなってしまいました。正解は、ディレクトリ単位で監視をすることだったのですが、こういう、知らないとハマりがちな問題は、AIだけでは解決に時間がかかりますね。動的更新の実装には2日ほどかかりました。
メトリクスデータの持ち方も悩みながら試行錯誤したところです。AsparaではいまはシンプルにJSONLフォーマットのみをサポートし、試験的にParquet形式も一応サポートしています。ここまでたどり着く前には紆余曲折があり、PyIceberg(pyarrow)やDuckDBなど、いろいろな選択肢を試しました。試行錯誤のさなかにPolarsのpl.read_ndjsonが信じられないくらい高速だということに気づき、現在の形に落ち着きました。
ライセンス
ライセンスは現時点ではApache-2.0ライセンスです。本体のライセンスはOSSにしたまま、SaaSの提供や監査機能を別モジュールで提供することで、商売にしていきたいと考えています。ただ、それらで十分な収益が得られない場合は、将来的には別のライセンスを選択せざるを得ないかもしれません。しかし、できるだけOSI承認のOSSライセンスを維持したいと考えています。
お仕事募集中
PredNextでは現在、お仕事のご依頼を募集しています。自然言語処理や画像処理などのAI技術が得意で、特に軽量化・高速化を強みにしています。Asparaの使い方のコンサルティングにももちろん対応いたします。ご興味のある方はお問い合わせフォームからご連絡ください。