For Those Who Just Want to Stare at Loss Functions — Meet Aspara
Today, PredNext has released Aspara, a metrics tracker for machine learning experiments, as open-source software.
Aspara is a new metrics tracker for those who find solace in quietly watching their loss functions. We focused on two key aspects:
- Getting to the loss function graph screen as quickly as possible
- Real-time and fast graph updates
- No slowdowns, even with months of experiment data
In addition to a standard web dashboard, Aspara also provides a TUI dashboard. Use whichever you prefer.
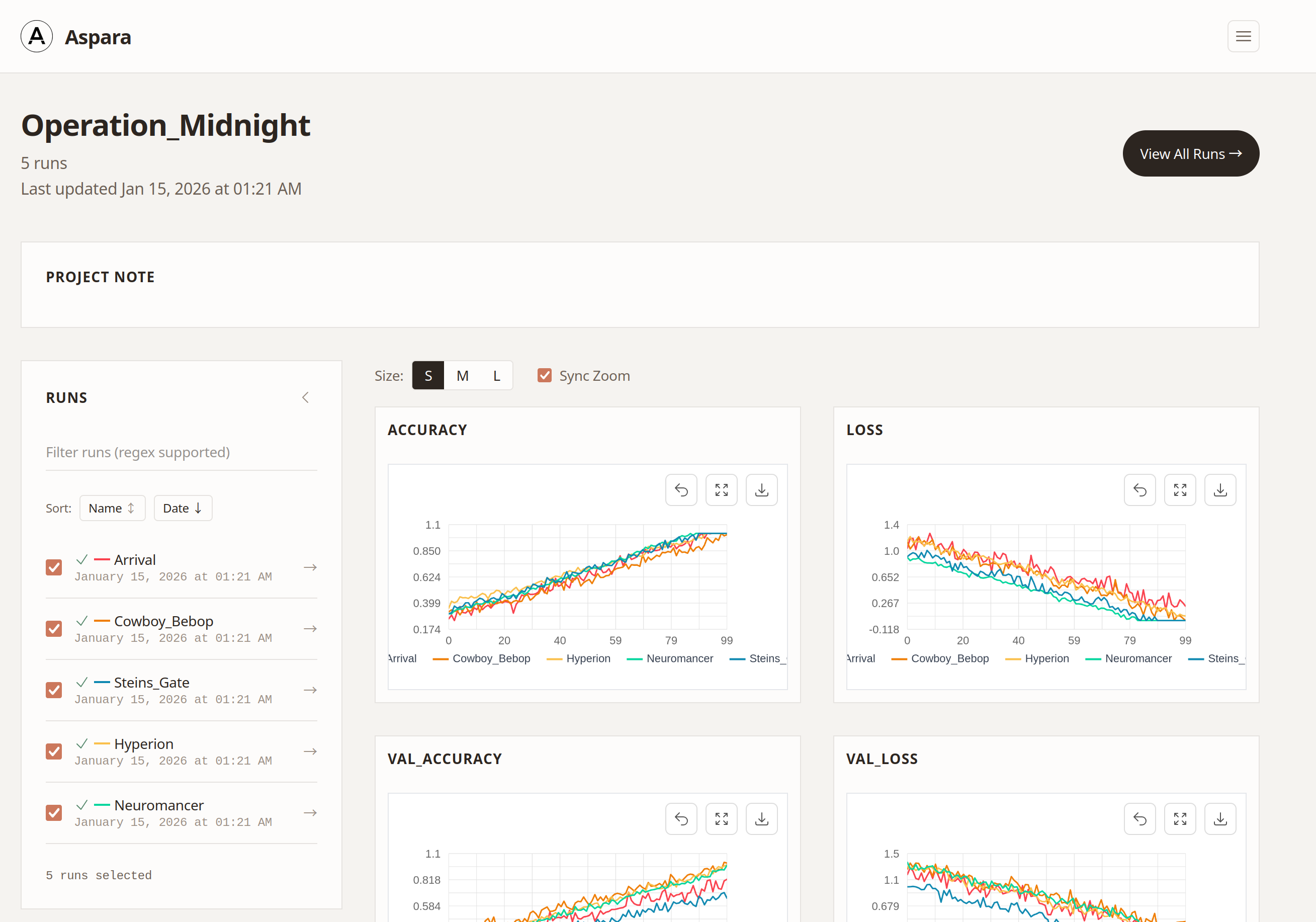
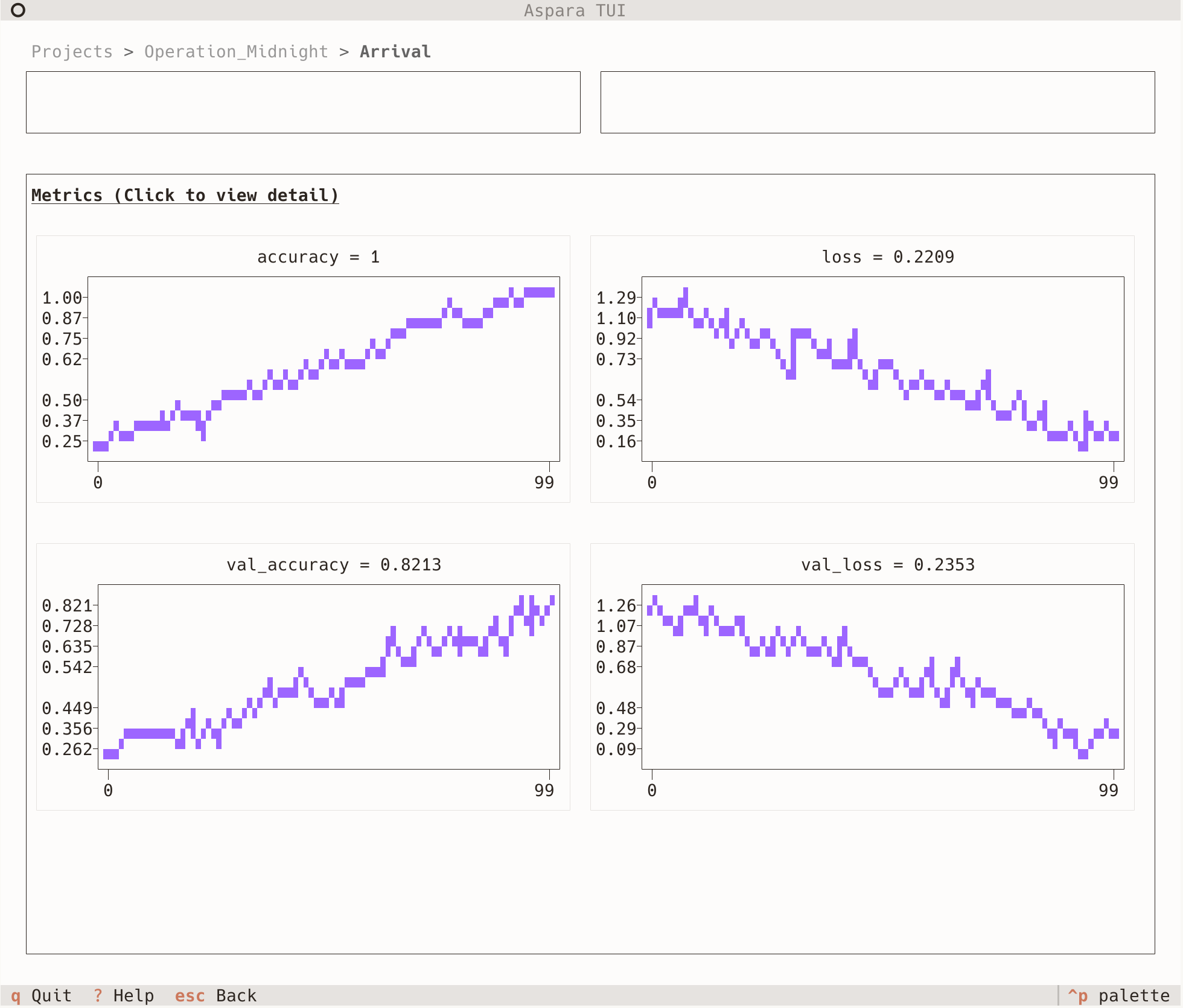
Aspara incorporates several clever techniques, and in this article, we’ll explain the most distinctive one: Largest Triangle Three Buckets (LTTB).
Downsampling with LTTB
Among the performance optimizations implemented in Aspara, LTTB-based data downsampling is particularly effective. To maintain screen responsiveness even with large amounts of metrics, we don’t send all metrics data to the browser — only the amount needed for display is transferred.
However, simply thinning out data might cause you to miss important changes. In metrics trackers, outliers matter more than averages. If there’s a spike in the loss function, you want to capture it. That’s why Aspara uses LTTB to preserve outliers.
In LTTB, data is divided into several buckets (intervals), and a representative point is selected for each bucket.
First, the first and last buckets use the first and last data points respectively. When determining the representative point for the second bucket onward:
- The previous bucket’s representative point (A — in this case, the first point)
- A candidate point in the current bucket (B)
- The average coordinates of the next bucket (C)
The area of the triangle formed by these three points is calculated, and the candidate point that produces the largest area is selected as the representative point for the current bucket. The same calculation is repeated for subsequent buckets.

LTTB’s computational complexity is O(N), where N is the number of data points. By adopting LTTB, even when the original data reaches tens of megabytes, the amount of data sent to the browser is compressed to about 1/100th, enabling transfer in just tens of milliseconds.
While LTTB is useful, it’s not a silver bullet. Since the representative point of the previous bucket must be determined before the current bucket’s representative point can be calculated, it’s difficult to compute entirely with numpy alone. A Python loop is required, which makes the computation somewhat heavier. Going forward, we plan to either rewrite this part in Rust or modify the algorithm itself to increase parallelism — in any case, we want to improve it further. There’s still room to make it faster, so stay tuned.
Recording Metrics
Aspara records metrics to local disk by default, but you can also send metrics via HTTP(S) by specifying a remote server address. Currently, only a Python client library exists, but we plan to provide client libraries for other languages in the future.
Behind the Development
About 99% of Aspara’s code was written by Claude Code and Windsurf. Aspara’s development took about two months in practice, and we were able to reach this release at this speed thanks to LLMs writing the code.
There were various challenges during development. The most difficult part was chart rendering. Since I’m not very familiar with Canvas, I left the chart rendering entirely to Claude, but it didn’t go smoothly. While developing the initial version around February of last year, I had the web version of Claude rewrite it about 50 times. (Claude Code came out shortly after that.)
The second most difficult challenge was dynamic chart updates. We use inotify to monitor file changes, but in the initial implementation, we attached a monitor to each run file, which exhausted file descriptors and quickly prevented update detection. The solution was to monitor at the directory level, but these kinds of gotcha problems that you wouldn’t know unless you’ve encountered them before take time to solve with AI alone. Implementing dynamic updates took about two days.
The approach to storing metrics data was also something we experimented with through trial and error. Aspara primarily supports the JSONL format, with experimental Parquet support also available. Before arriving at this solution, there were many twists and turns — we tried various options including PyIceberg (pyarrow) and DuckDB. During this experimentation, we discovered that Polars’ pl.read_ndjson is incredibly fast, and we settled on the current approach.
License
The license is currently Apache-2.0. We plan to keep the core under an OSS license while monetizing through SaaS offerings and audit features provided as separate modules. However, if those don’t generate sufficient revenue, we may need to consider a different license in the future. Nevertheless, we want to maintain an OSI-approved OSS license as much as possible.
Available for Projects
PredNext is currently accepting project requests. Our specialty is AI-related technologies centered on natural language processing and image processing, with a particular focus on model compression and acceleration. We’re also happy to provide consulting on how to use Aspara. If you’re interested, please contact us through our contact form.